Notice: Undefined index: alg in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 81
Notice: Undefined index: url2 in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 83
Notice: Undefined index: url3 in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 84
Notice: Undefined index: url4 in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 85
Notice: Undefined index: title in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 86
Notice: Undefined index: opurl2 in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 88
Notice: Undefined index: opurl3 in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 89
Notice: Undefined index: opurl4 in /home/u681245571/domains/studyglance.in/public_html/labprograms/mldisplay.php on line 90
Machine Learning - Lab Programs
Aim:
Source Code:
Week4.py
'''Aim: Given the following data, which specify classifications for nine ombinationsof VAR1 and VAR2 predict a classification for a case where VAR1=0.906and VAR2=0.606, using the result of k-means clustering with 3 means (i.e., 3centroids)
=================================
Explanation:
=================================
===> To run this program you need to install the sklearn Module
===> Open Command propmt and then execute the following command to install sklearn Module
---> pip install scikit-learn
In this program, we are going to use the following data
VAR1 VAR2 CLASS
1.713 1.586 0
0.180 1.786 1
0.353 1.240 1
0.940 1.566 0
1.486 0.759 1
1.266 1.106 0
1.540 0.419 1
0.459 1.799 1
0.773 0.186 1
And, we need apply k-means clustering with 3 means (i.e., 3 centroids)
Finally, you need to predict the class for the VAR1=0.906 and VAR2=0.606
===============================
Source Code :
===============================
'''
from sklearn.cluster import KMeans
import numpy as np
X = np.array([[1.713,1.586], [0.180,1.786], [0.353,1.240],
[0.940,1.566], [1.486,0.759], [1.266,1.106],[1.540,0.419],[0.459,1.799],[0.773,0.186]])
y=np.array([0,1,1,0,1,0,1,1,1])
kmeans = KMeans(n_clusters=3, random_state=0).fit(X,y)
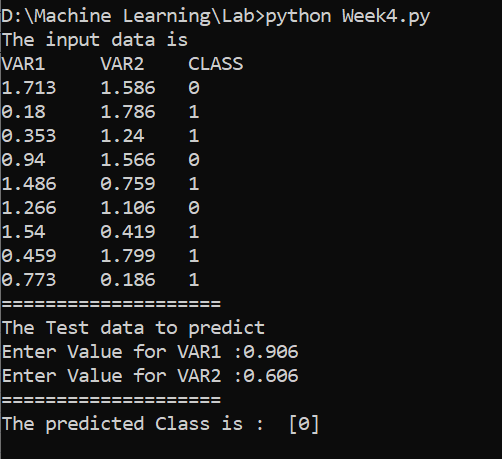
print("The input data is ")
print("VAR1 \t VAR2 \t CLASS")
i=0
for val in X:
print(val[0],"\t",val[1],"\t",y[i])
i+=1
print("="*20)
# To get test data from the user
print("The Test data to predict ")
test_data = []
VAR1 = float(input("Enter Value for VAR1 :"))
VAR2 = float(input("Enter Value for VAR2 :"))
test_data.append(VAR1)
test_data.append(VAR2)
print("="*20)
print("The predicted Class is : ",kmeans.predict([test_data]))Output:
Related Content :
Machine Learning Lab Programs
1) The probability that it is Friday and that a student is absent is 3%. Since there are 5 school days in a week, the probability that it is Friday is 20%. What is theprobability that a student is absent given that today is Friday? Apply Baye’s rule in python to get the result.(Ans: 15%) View Solution
&alg=&opurl1=ml/outputs/w1.PNG&opurl2=&opurl3=&opurl4=){kind=link}
2) Extract the data from database using python View Solution
{kind=link}
3) Implement k-nearest neighbours classification using python View Solution
{kind=link}
4) Given the following data, which specify classifications for nine ombinations of VAR1 and VAR2 predict a classification for a case where VAR1=0.906 and VAR2=0.606, using the result of k-means clustering with 3 means (i.e., 3 centroids) View Solution
&alg=&opurl1=ml/outputs/w4.PNG&opurl2=&opurl3=&opurl4=){kind=link}
5) The following training examples map descriptions of individuals onto high, medium and low credit-worthiness.Input attributes are (from left to right) income, recreation, job, status, age-group, home-owner. Find the unconditional probability of 'golf' and the conditional probability of 'single' given 'medRisk' in the dataset View Solution
 income, recreation, job, status, age-group, home-owner. Find the unconditional probability of 'golf' and the conditional probability of 'single' given 'medRisk' in the dataset&alg=&opurl1=ml/outputs/w5.PNG&opurl2=&opurl3=&opurl4=){kind=link}
6) Implement linear regression using python View Solution
{kind=link}
7) Implement naive baye's theorem to classify the English text View Solution
{kind=link}
8) Implement an algorithm to demonstrate the significance of genetic algorithm View Solution
9) Implement the finite words classification system using Back-propagation algorithm View Solution
{kind=link}