Machine Learning - (LAB PROGRAMS)
☛ Implementation of Decision tree using sklearn and its parameter tuning.
Solution :
A Decision Tree is a supervised machine learning algorithm used for classification and regression tasks. It builds a tree-like model of decisions based on features of the data, splitting nodes based on conditions that maximize information gain or minimize impurity. Decision Trees are interpretable and useful for understanding the structure of data.
Dataset Overview
The Iris dataset is a well-known dataset in machine learning, containing 150 samples from three species of Iris flowers: setosa, versicolor, and virginica. Each sample has four features: sepal length, sepal width, petal length, and petal width.
Steps :
1. Importing Required Libraries:
- Libraries from sklearn are imported for data handling, model training, evaluation, and visualization.
matplotlib.pyplotis used for plotting the decision tree.load_iris: To load the Iris dataset.train_test_split: To split the dataset into training and testing subsets.GridSearchCV: To perform hyperparameter tuning through grid search.DecisionTreeClassifier: To create a Decision Tree model.accuracy_scoreandclassification_report: To evaluate model performance.tree: For plotting the tree structure.
2. Loading the Iris Dataset
- The Iris dataset is loaded using
load_iris(). Xholds the feature data, andyholds the target labels (species of iris).
3. Splitting the Dataset
- Using
train_test_split, 90% of the data is used for training and 10% for testing. - This ensures the model is evaluated on unseen data.
4. Defining a Parameter Grid for Tuning
- criterion: Function to measure split quality - 'gini' or 'entropy'.
- max_depth: Max depth of the tree (1 to 4).
- min_samples_split: Minimum samples to split an internal node.
- min_samples_leaf: Minimum samples required at a leaf node.
5. Initializing the Decision Tree Classifier
- An instance of
DecisionTreeClassifieris created with a fixed random state.
6. Performing Grid Search for Parameter Tuning
GridSearchCVsearches through the parameter grid using cross-validation (cv=3).- It identifies the best combination of parameters for optimal model performance.
7. Getting the Best Model
best_estimator_retrieves the best-performing classifier from the grid search.
8. Fitting the Best Classifier on Training Data
- The best classifier is trained using
fit()onX_trainandy_train.
9. Making Predictions on the Test Set
- Predictions are made using the best model from the grid search.
10. Calculating Accuracy
accuracy_scoreis used to evaluate the model's prediction accuracy.
11. Printing Classification Report
classification_reportprovides precision, recall, and F1-score for each iris species class.
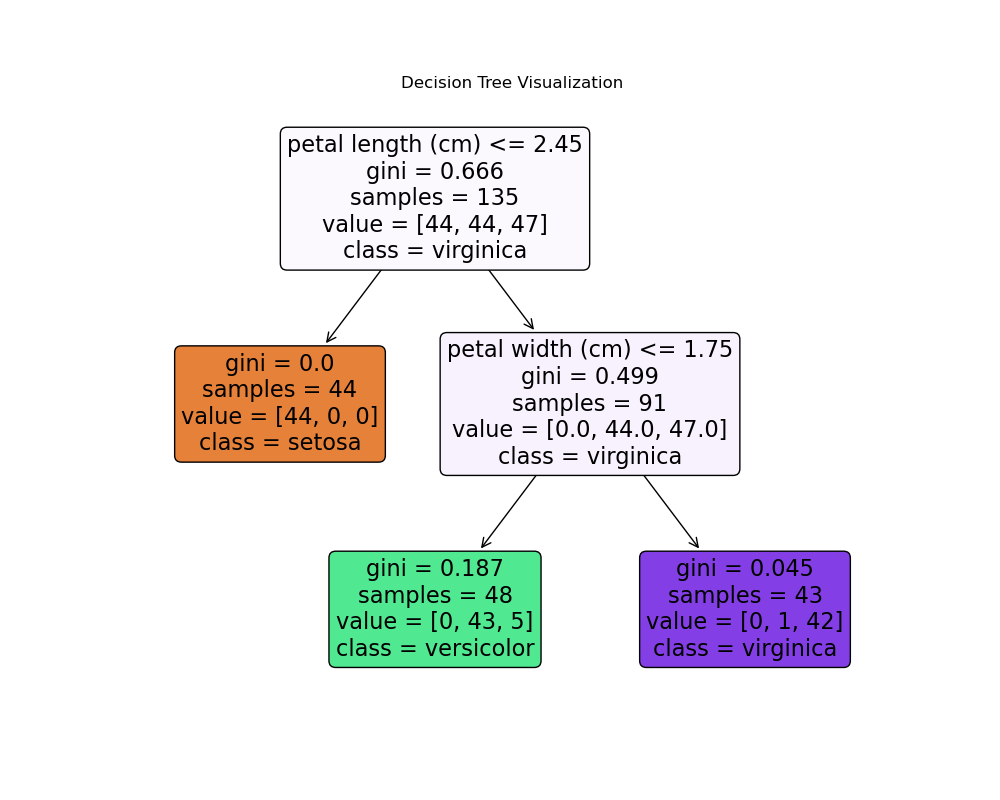
12. Visualizing the Best Decision Tree
plot_treefromsklearn.treeis used to visualize the tree structure.- It includes class names, feature names, and colored nodes for interpretability.
plt.show()displays the tree plot.
Library Installation:
To install required library files, Open Command Prompt or Terminal and execute the following commands
$ pip install scikit-learn
$ pip install matplotlib
Source Code:
File Name: Dtree.py
# Importing required libraries
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
from sklearn import tree
# Load the Iris dataset
iris = load_iris()
X = iris.data # Features
y = iris.target # Target labels
# Split the dataset into training and testing sets (90% train, 10% test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42) # 10% test size
# Initialize the Decision Tree classifier with some tuning parameters
clf = DecisionTreeClassifier(max_depth=2, min_samples_split=2, min_samples_leaf=1, random_state=42)
# Fit the classifier on the training data
clf.fit(X_train, y_train)
# Make predictions on the test set
y_pred = clf.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# Print classification report
print('Classification Report:')
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# Visualize the Decision Tree
plt.figure(figsize=(10, 8))
tree.plot_tree(clf, filled=True, feature_names=iris.feature_names,class_names=iris.target_names, rounded=True)
plt.title("Decision Tree Visualization")
plt.show()
Output:
Sample Run:
--------------
$ python3 Dtree.py
Accuracy: 1.00
Classification Report:
precision recall f1-score support
setosa 1.00 1.00 1.00 6
versicolor 1.00 1.00 1.00 6
virginica 1.00 1.00 1.00 3
accuracy 1.00 15
macro avg 1.00 1.00 1.00 15
weighted avg 1.00 1.00 1.00 15
Related Content :
Machine Learning Lab Programs
1) Write a python program to compute
• Central Tendency Measures: Mean, Median,Mode
• Measure of Dispersion: Variance, Standard Deviation View Solution
2) Study of Python Basic Libraries such as Statistics, Math, Numpy and Scipy View Solution
3) Study of Python Libraries for ML application such as Pandas and Matplotlib View Solution
4) Write a Python program to implement Simple Linear Regression View Solution
5) Implementation of Multiple Linear Regression for House Price Prediction using sklearn View Solution
6) Implementation of Decision tree using sklearn and its parameter tuning View Solution
7) Implementation of KNN using sklearn View Solution
8) Implementation of Logistic Regression using sklearn View Solution
9) Implementation of K-Means Clustering View Solution
10) Performance analysis of Classification Algorithms on a specific dataset (Mini Project) View Solution