Multi-Task Learning
Multi-Task Learning is a sub-field of Deep Learning that aims to solve multiple different tasks at the same time, by taking advantage of the similarities between different tasks. This can improve the learning efficiency and also act as a regularizer which we will discuss in a while.
Formally, if there are n tasks (conventional deep learning approaches aim to solve just 1 task using 1 particular model), where these n tasks or a subset of them are related to each other but not exactly identical, Multi-Task Learning (MTL) will help in improving the learning of a particular model by using the knowledge contained in all the n tasks.
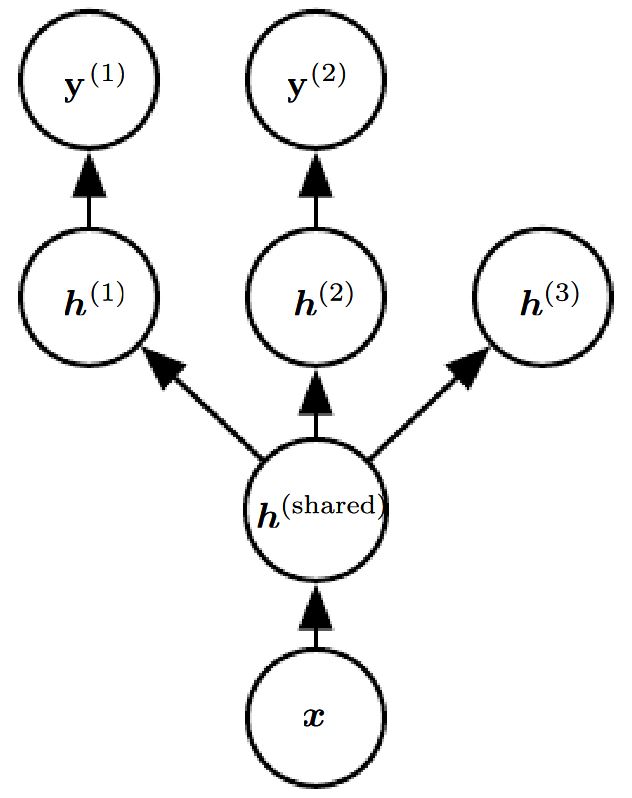
The different supervised tasks (predicting y(i) given x) share the same input x, as well as some intermediate-level representation h(shared) capturing a common pool of factors (Common input but different target random variables). Task-specific parameters h(1), h(2) can be learned on top of those yielding a shared representation h(shared). Common pool of factors explain variations of Input x while each task is associated with a Subset of these factors.
In the unsupervised learning context, some of the top level factors are associated with none of the output tasks h(3). These are factors that explain some of the input variations but not relevant for predicting h(1), h(2)
The model can generally be divided into two kinds of parts and associated parameters:
- Task-specific parameters (which only benefit from the examples of their task to achieve good generalization). These are the upper layers of the neural network.
- Generic parameters, shared across all the tasks (which benefit from the pooled data of all the tasks). These are the lower layers of the neural network.
Benefits of multi-tasking Improved generalization and generalization error bounds. Achieved due to shared parameters for which statistical strength can be greatly improved in proportion to the increased no.of examples for the shared parameters compared to the scenario of single-task models. From the point of view of deep learning, the underlying prior belief is the following: Among the factors that explain the variations observed in the data associated with different tasks, some are shared across two or more tasks
Next Topic :Early stopping