 Basics
Basics - A Historical Perspective
- File Systems v/s DBMS
- Data Models
- Levels of Abstraction
- Structure of DBMS
- Database Design
- Database Design
- ER Diagrams
- Attributes
- Entity
- Relationships
- Additional Features of the ER Model
- Relational Model
- Introduction to the Relational Model
- Integrity constraint over relations
- Enforcing Integrity Constraints
- Querying Relational Data
- Views
- Relational Algebra
- Tuple Relational Calculus
- SQL
- Form of basic SQL query
- UNION
- INTERSECT
- EXCEPT
- Aggregation Operators
- Complex Integrity Constraints in SQL
- Triggers and Active data bases
- Schema Refinement
- Problems caused by redundancy
- Decompositions and its problems
- Functional Dependencies and its reasoning
- Introduction to Normal Forms
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce-Codd Normal Form (BCNF)
- Fourth Normal Form (4NF)
- Fifth Normal Form (5NF or PJNF)
- Sixth Normal Form (6NF)
- Transaction
- Transaction Concept
- Transaction State
- Implementation of Atomicity and Durability
- Concurrent Executions
- Serializability
- Recoverability
- Implementation of Isolation
- Lock Based Protocols
- Timestamp Based Protocols
- Validation Based Protocols
- Multiple Granularity
- Recovery and Atomicity in dbms
- Recovery with Concurrent Transactions
- Indexing
- Data on External Storage
- File Organization and Indexing
- Cluster Indexes
- Primary Indexes
- Secondary Indexes
- Index data Structures
- Comparison of File Organizations, Indexes and Performance Tuning
- Indexed Sequential Access Methods
- Dynamic Index Structure - B+ Tree
Cluster Indexes in DBMS
A clustered index determines the physical order of data in a table. In other words, the order in which the rows are stored on disk is the same as the order of the index key values. There can be only one clustered index on a table, but the table can have multiple non-clustered (or secondary) indexes.
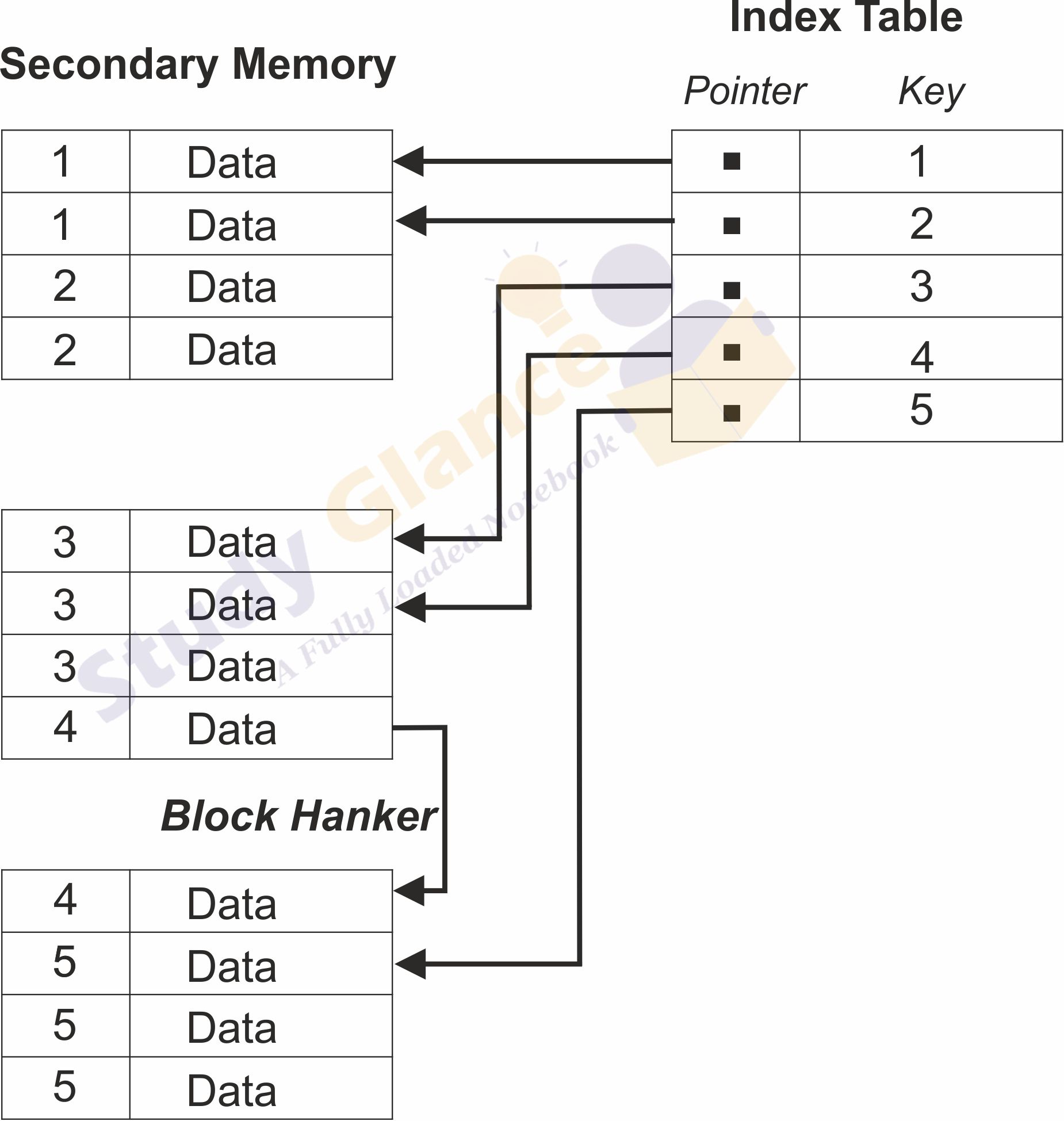
Characteristics of a Clustered Index:
- It dictates the physical storage order of the data in the table.
- There can only be one clustered index per table.
- It can be created on columns with non-unique values, but if it's on a non-unique column, the DBMS will usually add a uniqueifier to make each entry unique.
- Lookup based on the clustered index is fast because the desired data is directly located without the need for additional lookups (unlike non-clustered indexes which require a second lookup to fetch the data).
Clustered Index Example
Imagine a `Books` table with the following records:
| BookID | Title | Genre |
|--------|----------------------|-----------|
| 3 | A Tale of Two Cities | Fiction |
| 1 | Database Systems | Academic |
| 4 | Python Programming | Technical |
| 2 | The Great Gatsby | Fiction |If we create a clustered index on `BookID`, the physical order of records would be rearranged based on the ascending order of `BookID`.
The table would then look like this:
| BookID | Title | Genre |
|--------|----------------------|-----------|
| 1 | Database Systems | Academic |
| 2 | The Great Gatsby | Fiction |
| 3 | A Tale of Two Cities | Fiction |
| 4 | Python Programming | Technical |Now, when you want to find a book based on its ID, the DBMS can quickly locate the data because the data is stored in the order of the BookID.
Benefits of a Clustered Index:
- Fast Data Retrieval: Because the data is stored sequentially in the order of the index key, range queries or ordered queries can be very efficient.
- Data Pages: With the data being stored sequentially, the number of data pages that need to be read from the disk is minimized.
- No Additional Lookups: Once the key is located using the index, there's no need for additional lookups to fetch the data, as it is stored right there.
Drawbacks of a Clustered Index:
- Overhead on Inserts/Updates: Because the data must be stored physically in the order of the index keys, inserts or updates can be slower since they might require data pages to be rearranged.
- Single Clustered Index: You can have only one clustered index per table, so you have to choose wisely based on the most critical queries' requirements.
In practice, it's often beneficial to have the primary key of a table also be the clustered index, but this is not a requirement. The decision of which column to use as a clustered index should be based on query patterns, the nature of the data, and the characteristics of the application using the database.
Next Topic :Primary Indexes in DBMS