 TUTORIAL
TUTORIAL- Introduction
- Basic models
- Terminologies
- Supervised Learning Networks
- Perceptron Networks
- Adaptive Linear Neuron
- Back Propagation
- Associate Memory Network
- Bidirectional Associative Memory
- Hopfield Networks
- Unsupervised Learning
- Fixed Weight Competitive Networks
- Kohonen Self-Organizing Feature Maps
- Learning Vector Quantization
- Counter Propagation Networks
Adaptive Linear Neuron
Adaptive Linear Neuron (Adaline)
Adaline which stands for Adaptive Linear Neuron, is a network having a single linear unit. It was developed by Widrow and Hoff in 1960. Some important points about Adaline are as follows −
- It uses bipolar activation function.
- Adaline neuron can be trained using Delta rule or Least Mean Square(LMS) rule or widrow-hoff rule
- The net input is compared with the target value to compute the error signal.
- on the basis of adaptive training algoritham weights are adjusted
The basic structure of Adaline is similar to perceptron having an extra feedback loop with the help of which the actual output is compared with the desired/target output. After comparison on the basis of training algorithm, the weights and bias will be updated.
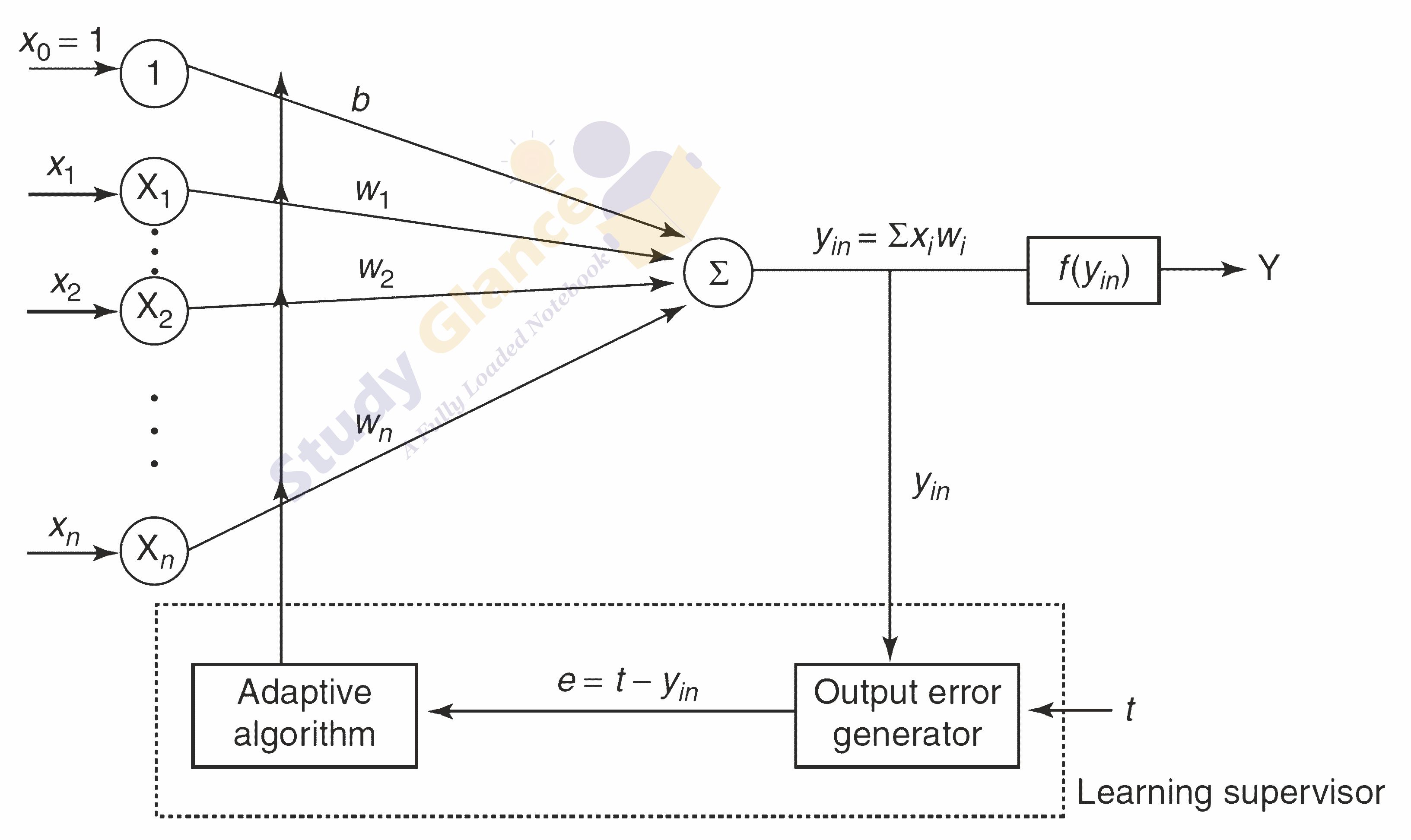
Adaptive Linear Neuron Learning algorithm
Step 0: initialize the weights and the bias are set to some random values but not to zero, also initialize the learning rate α.
Step 1 − perform steps 2-7 when stopping condition is false.
Step 2 − perform steps 3-5 for each bipolar training pair s:t.
Step 3 − Activate each input unit as follows −
Step 4 − Obtain the net input with the following relation −
Here ‘b’ is bias and ‘n’ is the total number of input neurons.
Step 5 Until least mean square is obtained (t - yin), Adjust the weight and bias as follows −
wi(new) = wi(old) + α(t - yin)xi
b(new) = b(old) + α(t - yin)
Now calculate the error using => E = (t - yin)2
Step 7 − Test for the stopping condition, if error generated is less then or equal to specified tolerance then stop.
Multiple Adaptive Linear Neuron (Madaline)
Madaline which stands for Multiple Adaptive Linear Neuron, is a network which consists of many Adalines in parallel. It will have a single output unit. Some important points about Madaline are as follows −
- It is just like a multilayer perceptron, where Adaline will act as a hidden unit between the input and the Madaline layer.
- The weights and the bias between the input and Adaline layers, as in we see in the Adaline architecture, are adjustable.
- The Adaline and Madaline layers have fixed weights and bias of 1.
- Training can be done with the help of Delta rule.
It consists of “n” units of input layer and “m” units of Adaline layer and “1” unit of the Madaline layer. Each neuron in the Adaline and Madaline layers has a bias of excitation “1”. The Adaline layer is present between the input layer and the Madaline layer; the Adaline layer is considered as the hidden layer.
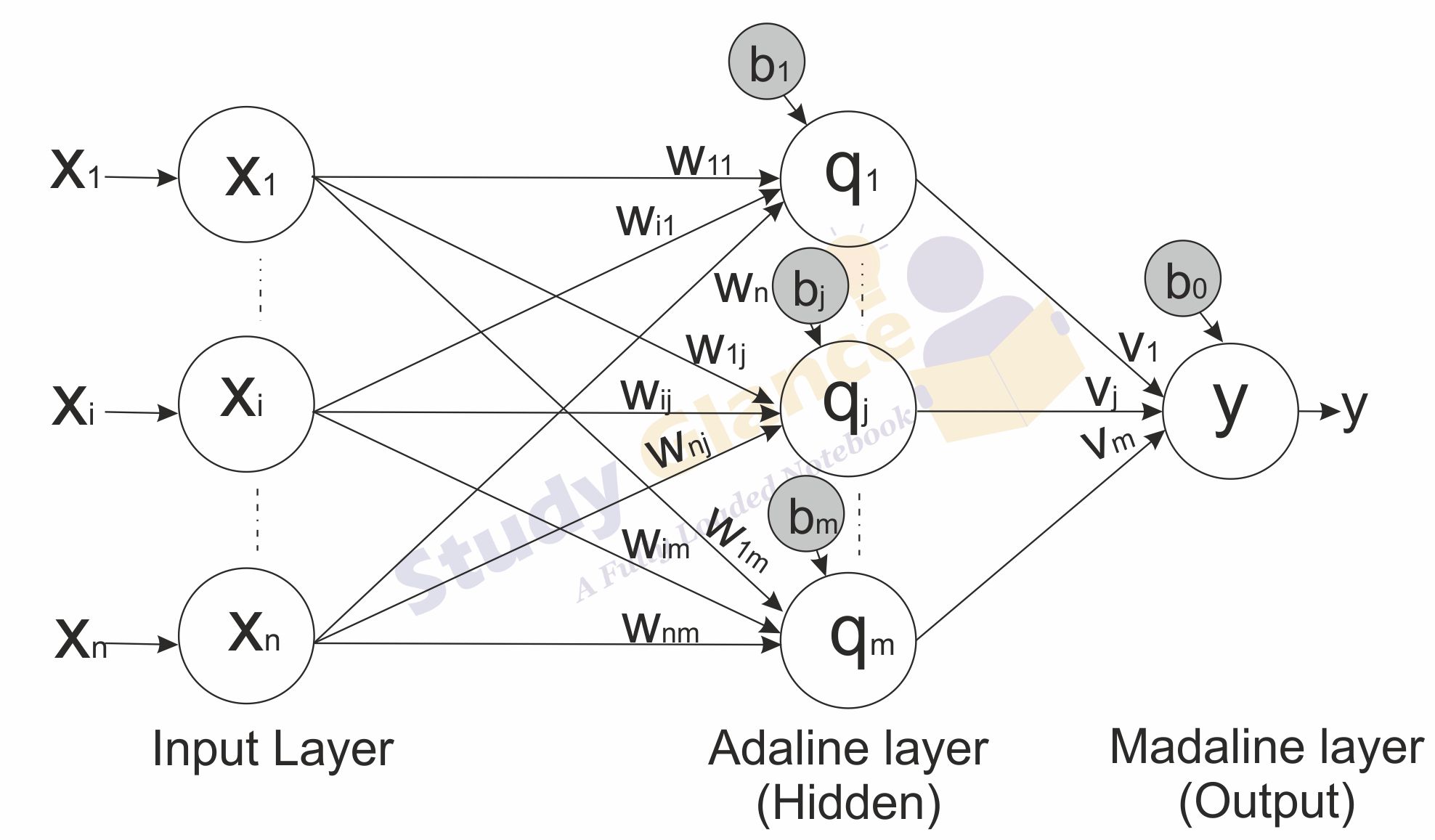
Multiple Adaptive Linear Neuron (Madaline) Training Algorithm
By now we know that only the weights and bias between the input and the Adaline layer are to be adjusted, and the weights and bias between the Adaline and the Madaline layer are fixed.
Step 0 − initialize the weights and the bias(for easy calculation they can be set to zero). also initialize the learning rate α(0, α, 1) for simpicity α is set to 1.
Step 1 − perform steps 2-6 when stopping condition is false.
Step 2 − perform steps 3-5 for each bipolar training pair s:t
Step 3 − Activate each input unit as follows −
Step 4 − Obtain the net input at each hidden layer, i.e. the Adaline layer with the following relation −
Here ‘b’ is bias and ‘n’ is the total number of input neurons.
Step 5 − Apply the following activation function to obtain the final output at the Adaline and the Madaline layer −
Output at the hidden (Adaline) unit
Final output of the network
i.e.
Step 6 − Calculate the error and adjust the weights as follows −
If t ≠ y and t = +1, update weights on Zj, where net input is closest to 0 (zero)
wij(new) = wij(old) + α(1 - Qinj)xi
bj(new) = bj(old) + α(1 - Qinj)
else If t ≠ y and t = -1, update weights on Zk, whose net input is positive
wik(new) = wik(old) + α(-1 - Qink)xi
bk(new) = bk(old) + α(-1 - Qink)
else if y = t then
no weight updation is required.
Step 7 − Test for the stopping condition, which will happen when there is no change in weight or the highest weight change occurred during training is smaller than the specified tolerance.
Next Topic :Back Propagation