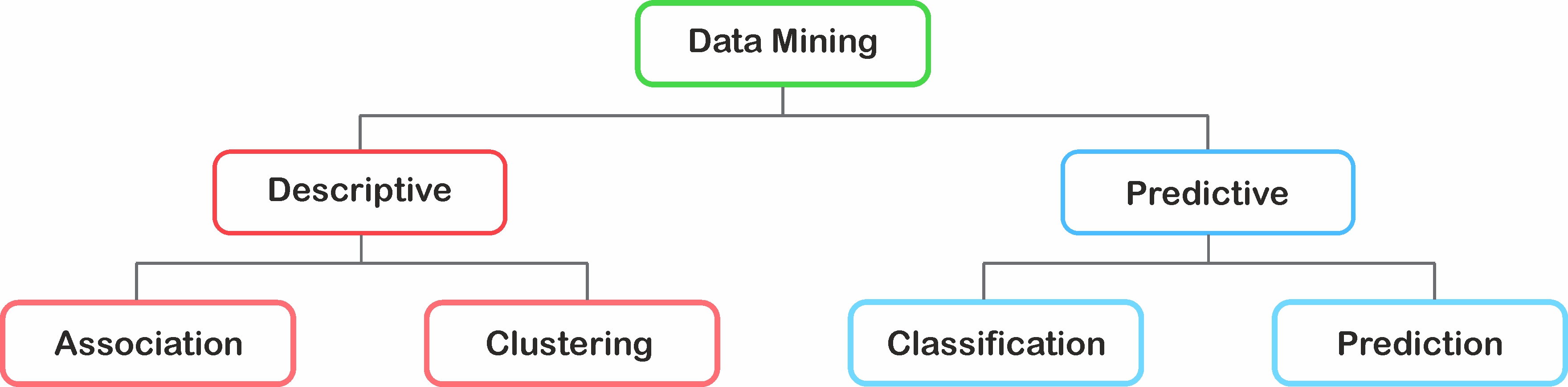
 Data Mining
Data Mining - Introduction
- Attribute Types
- Basic Statistical Descriptions of Data
- Knowledge Discovery from Data (KDD)
- Data Mining architecture
- Types of Data
- Data Mining Functionalities
- Interestingness Patterns
- Classification of Data Mining systems
- Data mining Task primitives
- Integration of Data mining system with a Data warehouse
- Major issues in Data Mining
- Data Preprocessing
- Association Rule Mining
- Mining Frequent Patterns
- Associations and correlations
- Mining Methods
- Apriori algorithm
- FP-Growth algorithm
- Mining Various kinds of Association Rules
- Correlation Analysis
- Constraint based Association mining
- Graph Pattern Mining
- SPM(Sequential Pattern Mining)
- Classification
- Basic concepts
- Decision tree induction
- Bayesian classification
- Rule–based classification
- Lazy learner(K-NN)
Data Mining Functionalities
Data mining is important because there is so much data out there, and it's impossible for people to look through it all by themselves.
Data mining uses various functionalities to analyze the data and find patterns, trends, and other information that would be hard for people to find on their own.
Data mining functionalities areused to specify the kinds of patterns to be found in data mining tasks.In general, such data mining tasks can be classified into two categories: descriptive and predictive.
Descriptive data mining
Similarities and patterns in data may be discovered using descriptive data mining.
This kind of mining focuses on transforming raw data into information that can be used in reports and analyses. It provides certain knowledge about the data,
for instance, count, average.
It gives information about what is happening inside the data without any previous idea. It exhibits the common features in the data. In simple words, you get to know the general properties of the data present in the database.Predictive data mining
These kind of mining tasks perform inference on the current data in order to make predictions.
This helps the developers in understanding the characteristics that are not explicitly available. For instance, the prediction of business analysis in the next quarter with the performance of the previous quarters. In general, the predictive analysis predicts or infers the characteristics with the previously available data.
The following are data mining functionalities:
- Class/Concept Description (Characterization and Discrimination)
- Classification
- Prediction
- Association Analysis
- Cluster Analysis
- Outlier Analysis
Class/Concept Description: Characterization and Discrimination
Data is associated with classes or concepts.
- Class: A collection of things sharing a common attribute
- Example: Classes of items – computers and printers
- Concept: An abstract or general idea derived from specific instances.
- Example: Concepts of customers – bigSpenders and budgetSpenders.
It can be useful to describe individual classesand concepts in summarized, concise, and yet precise terms. Such descriptions of a classor a concept are called class/concept descriptions.
These descriptions can be derivedusing data characterization and data discrimination, or both.
Data characterization
Data characterization is a summarization of the general characteristics or featuresof a target class of data.
Data summarization can be done based on statistical measures and plots.
The output of data characterization can be presented in various forms it includes pie charts, bar charts, curves, and multidimensional data cubes.
Example: A customer relationship manager at AllElectronics may order thefollowing data mining task: Summarize the characteristics of customers who spend morethan $5000 a year at AllElectronics.
The result is a general profile of these customers,such as that they are 40 to 50 years old, employed, and have excellent credit ratings.
Data discrimination
Data discrimination is one of the functionalities of data mining. It compares the data between the two classes. Generally, it maps the target class with a predefined group or class. It compares and contrasts the characteristics of the class with the predefined class using a set of rules called discriminate rules.
Example: A customer relationship manager at AllElectronics may want to compare two groups of customers those who shop for computer products regularly(e.g., more than twice a month) and those who rarely shop for such products (e.g.,less than three times a year).
The resulting description provides a general comparativeprofile of these customers, such as that 80% of the customers who frequently purchasecomputer products are between 20 and 40 years old and have a university education,whereas 60% of the customers who infrequently buy such products are either seniors oryouths, and have no university degree.
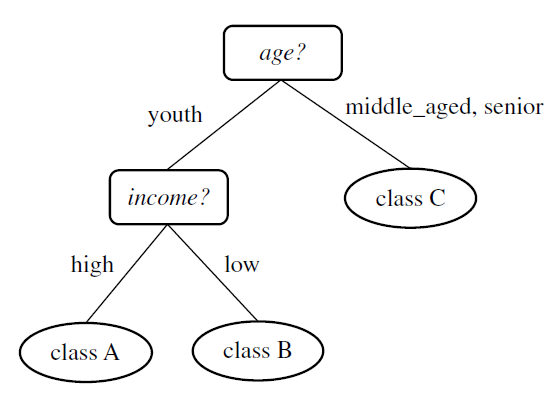
Classification
:Classification is a data mining technique that categorizes items in a collection based on some predefined properties. It uses methods like IF-THEN, Decision trees orNeural networks to predict a class or essentially classify a collection of items.
Classification is a supervised learning technique used to categorize data into predefined classes or labels.
Example:
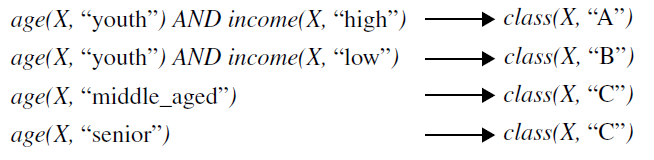
Prediction
Finding missing data in a database is very important for the accuracy of the analysis. Prediction is one of the data mining functionalities that help the analyst find the missing numeric values. If there is a missing class label, then this function is done using classification. It is very important in business intelligence and is very popular. One of the methods is to predict the missing or unavailable data using prediction analysis.
Example:
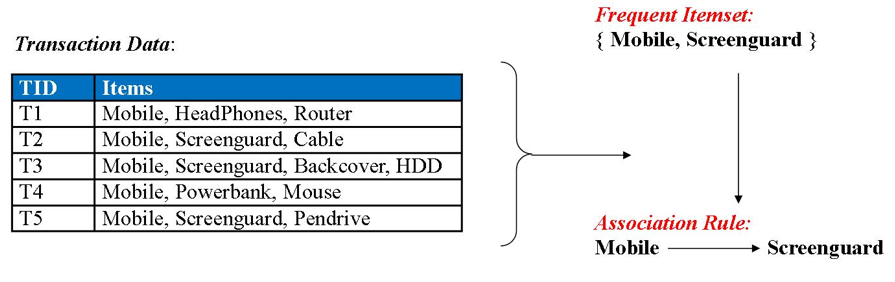
Association Analysis
Association Analysis is a functionality of data mining. It relates two or more attributes of the data. It discovers the relationship between the data and the rules that are binding them. It is also known as Market Basket Analysis for its wide use in retail sales.
The suggestion that Amazon shows on the bottom, “Customers who bought this also bought.” is a real-time example of association analysis.
It relates two transactions of similar items and finds out the probability of the same happening again. This helps the companies improve their sales of various items.
Cluster Analysis
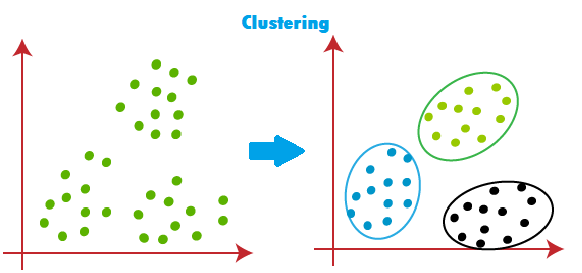
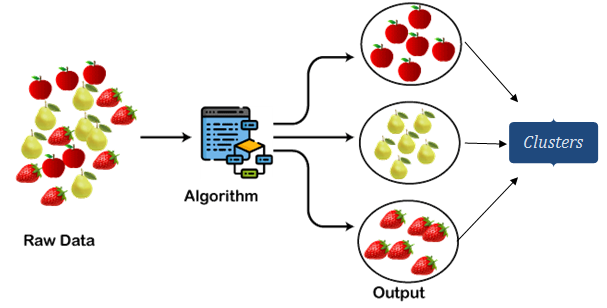
Clustering is an unsupervised learning technique that group’s similar data points together based on their features. The goal is to identify underlying structures or patterns in the data. Some common clustering algorithms include K-means, hierarchical clustering, and DBSCAN.
This data mining functionality is similar to classification. But in this case, the class label is unknown.Similar objects are grouped in a cluster. There are vast differences between one cluster and another.
Example1:
Example2:
Outlier Analysis
When data that cannot be grouped in any of the class appears, we use outlier analysis. There will be occurrences of data that will have different attributes/features to any of the other classes or clusters. These outstanding data are called outliers. They are usually considered noise or exceptions, and the analysis of these outliers is called outlier mining.
Outlier analysis is important to understand the quality of data. If there are too many outliers, you cannot trust the data or draw patterns out of it.
Example1:
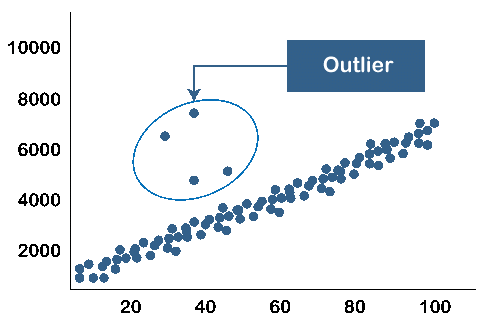
Example2:

Next Topic :Interestingness Patterns