 Data Structures
Data Structures - Introduction
- Abstract data types
- Linear Data Structures
- Linked List Introduction
- Single Linked List
- Stacks using Array
- Stacks using linkedlist
- Queues using array
- Queues using linkedlist
- Stack Applications
- Infix to Postfic Converstion
- Postfix Evaluation
- Dictionaries
- Introduction to Dictionaries
- Linear list representation
- Skip list representation
- Hash Table
- Introduction Hash Table
- Hash functions
- Collision Resolution
- Separate chaining
- Open addressing
- Rehashing
- Extendible hashing
- Trees
- Introduction to Tree
- Binary trees Representation
- Binary tree traversals
- Binary Search Tree
- AVL Tree
- Red Black Tree
- Splay Tree
- B Tree
- B+ Tree
- Comparison of Trees
- Graphs
- Introduction to Graph
- Graph Representation
- Breadth-First Search
- Depth-First Search
- Sorting
- Quick Sort
- Merge Sort
- Heap Sort
- Pattern Matching
- Introduction to pattern Matching
- Brute force Pattern Matching
- Boyer–Moore Pattern Matching
- KMP Pattern Matching
- Tries
- Introduction to Tries
- Standard Trie
- Compressed tries
- Suffix Trie
KMP Pattern Matching
The Knuth-Morris-Pratt (KMP) pattern matching algorithm is an efficient string searching method developed by Donald Knuth, James H. Morris, and Vaughan Pratt in the year 1970. It is used to find the occurrences of a "pattern" within a "text" without checking every single character in the text, which is a significant improvement over the brute-force approach.
The KMP algorithm compares the pattern to the text in left-to-right, but shifts the pattern, P more intelligently than the brute-force algorithm. When a mismatch occurs, what is the most we can shift the pattern so as to avoid redundant comparisons. The answer is that the largest prefix of P[0..j] that is a suffix of P[1.j].
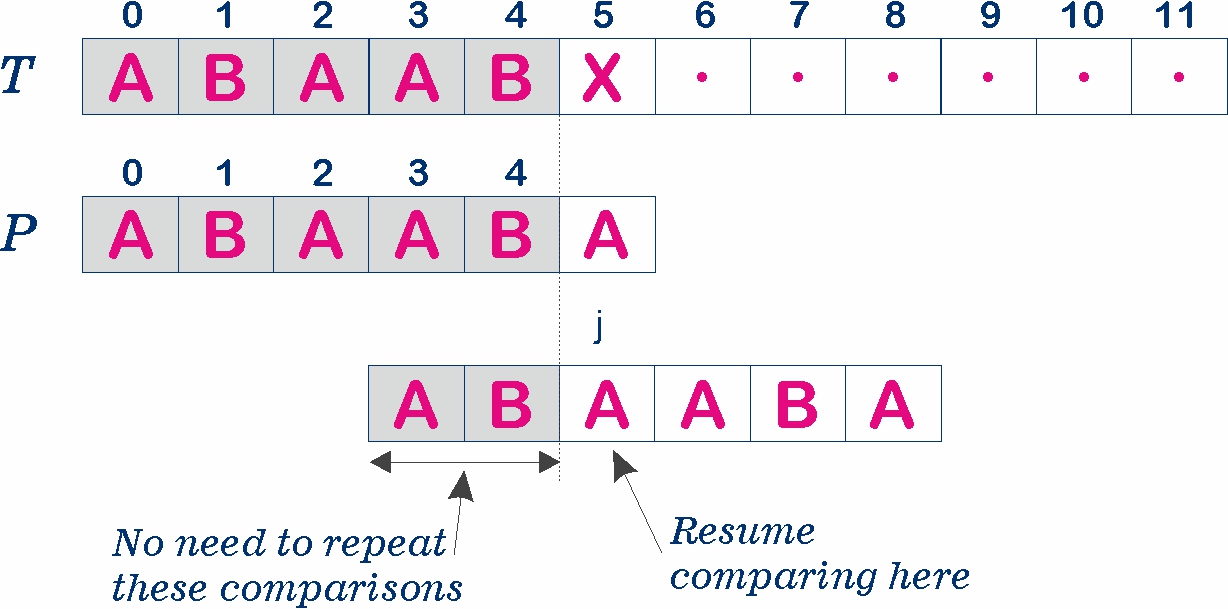
Here's a step-by-step explanation of how the KMP algorithm works:
1. Preprocessing(Building the LPS Array)
The core idea to preprocess the pattern to construct an LPS(Longest Prefix Suffix) array. This array stores the length of the longest proper prefix which is also a suffix for each sub-pattern of the pattern. This preprocessing helps in determining the next positions in the pattern to be compared, thus avoiding redundant comparisons.
- Start by initializing the first element of lps[] to 0, as a single character can't have any proper prefix or suffix.
- Maintain two pointers, len and i, where len is the length of the last longest prefix suffix. Initially, len := 0 and i := 1.
- Repeat steps 4 to 6, while (i < m)
- If pattern[len] equals pattern[i], set lps[i] = len + 1, increment both i and len.
- If they don't match and len is not 0, update len to lps[len - 1].
- If they don't match and len is 0, set lps[i] = 0 and increment i.

2. Searching
Once the preprocessing is done, the actual search begins:
- Align the pattern with the beginning of the text.
- Compare the pattern with the text from left to right.
- If all characters of the pattern match, a valid occurrence is found.
3. Shifting the Pattern:
- Compare pattern[j] with text[i].
- If they match, increment both i and j.
- If j equals the pattern length, a match is found. Optionally report the match, then set j to lps[j - 1].
- If they don't match and j is not 0, set j to lps[j - 1]. Do not increment i here.
- If they don't match and j is 0, increment i
4. Repeat Comparison
- Continue comparing the pattern with the text from left to right.
- Apply the shifting rules whenever a mismatch is encountered.
- Continue this process until the end of the text is reached or all occurrences of the pattern are found.
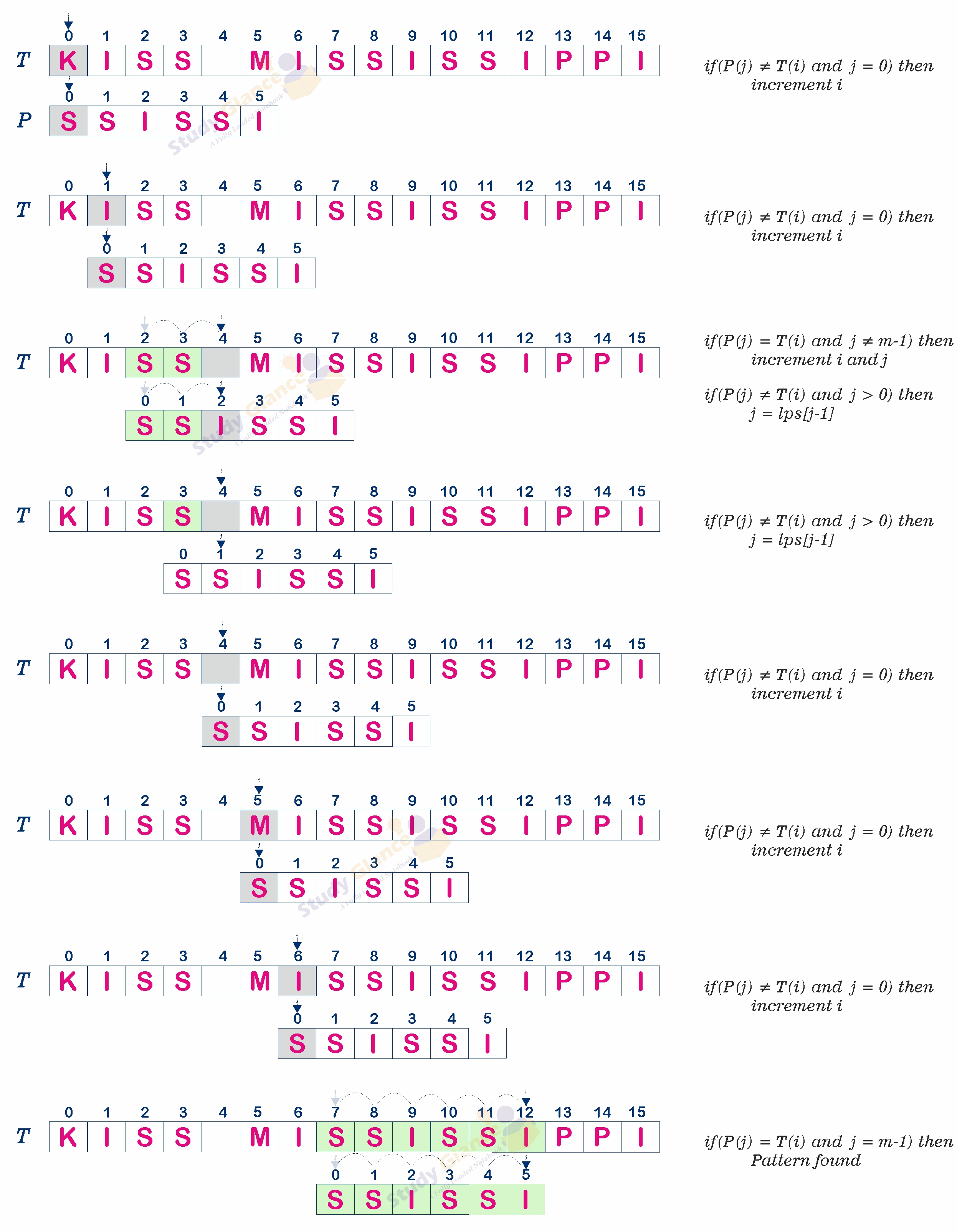
5. Termination
The algorithm terminates when either
- The pattern has been shifted past the end of the text, indicating no more matches are possible.
- All occurrences of the pattern has have been found.
Pseudo code for KMP Pattern Matching algorithm
Function KMP(T:text, P:pattern)
n: lenght of T, i: index of T
m: lenght of P, j: index of P
lps[j] is a array, for j=0 to m-1
lps[]=computeLPSArray(P)
i:=0, j:=0
while i < n
if(P(j) = T(i)) then
if(j = m-1)then
return true
increment i and j
else if(j > 0) then
j = lps[j-1]
else
increment i
return false
Function computeLPSArray(P:pattern)
m: lenght of P
len:=0, i:=1
while(i < m)
if(P[len] = P[i]) then
lps[i]=len+1;
increment len and i
else if(j>0) then
len=lps[len-1]
else
lps[i]=0
increment iNext Topic :Introduction to Tries